Meta which started out as a college networking app has developed and acquired over 94 other companies including WhatsApp, Instagram, and Messenger. It boasts of over $117B in revenue and $165B of assets in management.
The Meta interview process is one of the most difficult interviews in the tech industry. You should expect fairly ambiguous questions and scenarios that will test your past experience and technical skills using languages like SQL and potentially python. This article will take a closer look at what it takes to pass the Meta interview for analyst, business intelligence analyst, data engineers, and data analyst.
Facebook’s Most Common Data Science SQL Interview Question [2021 Interview Question and Answer]
Most Common Meta/Facebook Interview Format
Round 1: Recruiter phone screen
Overview
The recruiter phone screen is primarily focused on qualifying you as a candidate. On rare occasions, the recruiter will also ask you a few SQL interview questions, but the majority of the interview will be focused on understanding why you applied for the role, compensation expectations, and background.
Duration: 15 to 30 minutes
Most common Meta/Facebook behavioral questions
- Tell me about yourself?
- Why do you want to join Meta?
- Why did you apply for this job?
Most common Meta/Facebook SQL questions
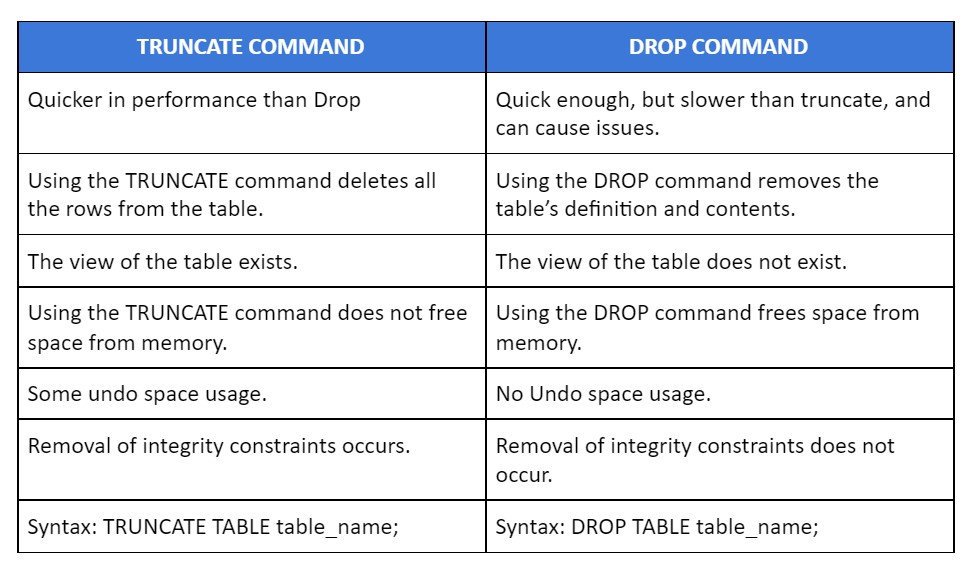
- What is the difference between a UNION and a UNION ALL?
- How would you explain how window functions work to a non-technical person?
Most common Meta/Facebook product/case questions
- How would you determine the best friends across Facebook users?
Round 2: Technical screening
Overview
Meta’s technical assessment is primarily focused on testing your SQL and product sense capabilities with various SQL questions and challenges. It’ll also potentially include Python, system design, machine learning (ML), and statistics-related questions if you’re interviewing for a data engineer, data analyst, or data science role. Fair warning, this is one of the most common places candidates get rejected. It won’t be an easier interview and you’ll need ample preparation to pass this round. It’s not uncommon for candidates to schedule this technical interview 2-3 weeks from their previous round in order to fully prepare.
Duration: 45 to 60 minutes
Most common Meta/Facebook technical questions
- Meta SQL interview questions
- Count the number of users for each disable_reason in the past 7 days?
- Meta Python interview questions*
- Given list [a,b,c,a,b,c] Please create a function that returns percentiles.
- Where each a b c are different
- Each a is lower bound
- Each b is upper bound
- Each c is count
- Given list [a,b,c,a,b,c] Please create a function that returns percentiles.
-
Meta Product/case questions
- What’s the problem with people having too many friends on Facebook?
- Meta Statistics questions*:
- How would you use the Bayesian Theorem to solve this confidence interval?
* Depending on your role you will have Python, product sense, and potentially Statistics. Check with your recruiter to be sure.
Round 3: Full loop (3 to 5 back-to-back interviews)
Overview
The final round of your Meta interview will consist of 3-5 senior to senior manager level employees who’ll challenge you with SQL, probability/statistics, product sense, and culture-related questions. I recommend you prepare similar to a product manager interview except without the focus on behavioral or leadership-related questions.
Duration: 135 to 225 minutes
Most common Meta/Facebook behavioral questions
- Tell me about a time when you had an idea you proposed was not agreed on.
- Describe a time when your project failed.
- When you didn’t have enough resources, how did you deliver products?
Most common Meta/Facebook SQL questions
- Write an SQL query to find the average daily percentage of emails that get removed after being reported as spam, rounded to 2 decimal places.
- Write an SQL query to report the client_id and client_name of clients who have spent at least $100 in each month of June and July 2019. Return the result table in any order.
- Write an SQL query to find the ids of items that are both dietary and reusable. Return the result table in any order.
Most common Meta/Facebook product/case questions
- What would you do if you see a drop in time spent on Facebook?
- How would you make the decision to roll out a new product or not?
- How would you evaluate the negative impact of a new notification release?
Most Common Meta/Facebook SQL Concepts
Joins and Unions
Joins
- INNER JOIN: Returns all rows from multiple tables where the join criteria is met.
- SELF JOIN: Returns combined rows from the same table. It is a situation where each row is attached to itself and other rows in the same table.
- LEFT JOIN: Returns all rows from the left table, and the matching rows from the right table.
- RIGHT JOIN: Returns all rows from the right table, and the matching rows from the left table.
- CROSS JOIN: Returns the Cartesian product of rows from the tables in the join. Said differently, it combines each row from the first table with each row from the second table.
Unions
- UNION: Returns the combined results with no duplicate rows of two or more SELECT statements.
- UNION ALL: Returns the results of two or more SELECT statements without removing the duplicate rows.
- INTERSECT: Returns the rows that are common to all the tables in the query.
- EXCEPT: Returns the rows in the first that are not in the second query.
Aggregating and Grouping Data
Beginner SQL Aggregations
- AVG: Returns the average of a column in the query.
- COUNT: Returns the number of items of a column in the query.
- MAX: Returns the maximum value of a column in the query.
- MIN: Returns the minimum value of a column in the query.
- SUM: Returns the sum of all or distinct values of a column in the query.
Intermediate SQL Aggregations
- DENSE_RANK: Returns the rank of a row in an ordered group of rows and returns the rank as a NUMBER.
- RANK: Returns the rank of a value in a group of values. The rank is one plus the number of rows preceding the row that are not peer with the row. Unlike DENSE_RANK, values that are the same in the ordering will produce gaps in the sequence.
- ROW_NUMBER: Returns a unique, sequential number for each row, starting with one, based on the order of the rows in the window partition.
- LEAD: Returns a row at a specified physical offset which follows the current row.
- LAG: Returns the previous rows data as per defined offset value.
Advanced SQL Aggregations
- STD SAMP: Returns the sample and population standard deviation of a set of numeric values (integer, decimal, or floating-point).
- STDEV: Used to calculate the Standard Deviation of total records (or rows) selected by the SELECT Statement.
- REGR_COUNT: Calculates the linear regression coefficient for the count of pairs of x and y values where x and y are not null.
- CUME_DIST: Returns the cumulative distribution of a value in a group of values. The result is the number of rows preceding and including the row in the window ordering of the window partition divided by the total number of rows in the window partition. Rows with the same values in the ordering will evaluate to the same distribution value.
Filtering & Ordering Data
Filtering Data
- WHERE: Used to filter records into rows before they are grouped. The data should specify or meet the mentioned condition, for example WHERE = PRICE > 365.
- HAVING: Used to filter the record from the groups based on the specified condition.
- LIMIT: Restricts how many rows are returned from the results.
- DISTINCT: Used in conjunction with the SELECT statement to remove all the duplicate records and returns only unique results.
Ordering Data
- ORDER BY ASC: Used to return the results in ascending order.
- ORDER BY DESC: Used to return the results in descending order.
Subqueries and Common Table Expressions (CTEs)
Subqueries
- SUBQUERY: Used as query within another SQL query and embedded within the WHERE clause. This is also called INNER query OR NESTED query.
Common Table Expressions (CTEs)
- CTE: Returns the results of a query which exists temporarily and for use only within the context of a larger query. It cannot be used in other queries even within the same session.
The Business Analyst Meta/Facebook Interview
Overview of Business Analyst at Meta/Facebook
- Compensation:
- Salary range: $100,000 to $132,000 USD
-
- Bonus: to $6,000 to $17,000
- Equity: $5,000 to $25,000
- Responsibilities:
- Lead the development of reporting, and insights to amplify the performance of teams such as sales, finance, or marketing.
- Own project optimization, lead prioritization, forecasting, or a variety of other domains supporting various teams.
- Provide business requirements and collaborate with internal teams on data capture strategy that will support accurate reporting and insights on sales patterns and consumer behavior.
- Define key performance metrics.
- Create reports and self-service dashboards to provide ongoing insight to business stakeholders, support leadership in making effective, analytically driven, and strategic decisions.
- Perform ad-hoc and in-depth analyses and then report/present insights.
- Automate reporting via SQL and Python-based ETL framework.
- Qualifications:
- BS Degree in Business, Economics, Statistics, Mathematics, Applied Mathematics, Finance, and other quantitative areas.
- 3+ years experience in sales/business reporting/analytics.
- Experience with visualizations and dashboards.
- Experience in querying and manipulating technical concepts and analysis implications clearly to varied audiences and to translate business objectives into actionable analyses.
- Experience working independently and as a member of a cross-functional team.
Round 1: Recruiter phone screen
Overview
Similar to the standard recruiter phone screen, the recruiter is focused on qualifying you as a candidate before moving you on to the next round. It’s typically 30 minutes and a great opportunity for you to get a better understanding of the role and why they’re hiring for it. Occasionally, analysts will report they were asked SQL or product sense questions in this round albeit it’s fairly rate. If you’re worried you’ll have a technical screen during this portion of the interview, ask your recruiter.
Duration: 15 to 30 minutes
Most common Meta/Facebook behavioral questions
- Why do you want to work at Meta?
- How do you comfortable with SQL and Python?
- Name one thing on your resume that you are proud to have worked on/contributed towards?
Most common Meta/Facebook product/case questions
- Instagram stories have gone down by 10%, how would you diagnose the root cause of this?
Round 2: Technical screening
Overview
Meta SQL interviews for business, product, or operations analysts are fairly similar as the core focus surrounds testing your SQL skills with advanced experience with data manipulation. For example, you’ll need to know how to effectively use SELF JOINS, HAVING, and WINDOW FUNCTIONS. Additionally, you’ll have the option to solve the questions using Python as well. It’s worth mentioning, that Meta is notorious for having fairly ambiguous SQL questions. It’s important that you remain calm and walk your interviewer through logic and assumptions. I’d recommend practicing this technical assessment round with a friend and speaking out loud as you answer the questions before your next interview.
Duration: 45 to 60 minutes
Most common Meta/Facebook technical questions
- Meta SQL interview questions
- What are the top five (ranked in decreasing order) single-channel media types that correspond to the most money the logistics startup has spent on its promotional campaigns?
- Of sales that had a legitimate advertisement, the head of finance wants to know what % of transactions occur on either the very first day or the very last day of a promotion campaign.
- Meta Python interview questions*
- Write a function to return the number of times a character appears in a string. The character can be the empty string.
-
Meta Product/case questions
- How would you design a new feature for Facebook?
* Certain analyst roles will not test your experience with Python.
Round 3: Full loop (3 to 5 back-to-back interviews)
Overview
The final round of your Meta analyst interview will consist of 3-5 Meta employees ranging from entry to senior level. There will be a mix of technical, product, and behavioral interviews. Expect to go deeper with experience with SQL, probability/statistics, product sense, and culture. Make sure to come prepared with relevant examples that relate to the role you’re interviewing for and to stick with the STAR format.
Duration: 135 to 225 minutes
Most common Meta/Facebook behavioral questions
- Why do you want to join Meta?
- Describe yourself in 3 words.
- What problems do you think Facebook faces with security?
- What interests you about this role?
Most common Meta/Facebook SQL questions
- Can you explain to me what linear regression is?
- What percent of all products in the logistic startup catalog are both low fat and recyclable?
- The COO is interested in understanding how the sales of different product families are affected by promotional campaigns. To do so, for each of the available product families, show the total number of units sold, as well as the ratio of units sold that had a valid advertisement to units sold without an advertisement, ordered by increasing order of total units sold.
Most common Meta/Facebook product/case questions
- We’re launching a new ads feature, how would you define the success metric?
- How would you decide if we should swap the launch of ads with a new e-comm panel?
- How would you create and validate a recommendations feed?
The Data Engineer Meta/Facebook Interview
Overview of Data Engineer at Meta/Facebook
- Compensation:
- Salary range: $100,000 to $132,000 USD
- Bonus: to $10,000 to $20,000
- Equity: $30,000 to $100,000
- Responsibilities:
- Partner with leadership, engineers, program managers, and data scientists to understand data needs.
- Lead, influence, and set direction on domain areas as a subject matter expert to drive complex solutions for strategic problems.
- Design, build and launch extremely efficient and reliable data pipelines to move data across a number of platforms including Data Warehouse, online caches, and real-time systems.
- Educate your partners: Use your data and analytics experience to ‘see what’s missing’, identifying and addressing gaps in their existing logging and processes.
- Leverage data and business principles to solve large-scale web, mobile, and data infrastructure problems.
- Contribute to shared Data Engineering tooling and standards to improve the productivity and quality of output for Data Engineers across the company.
- Actively mentor and identify rising talent, and serve as a positive leader across the scope of the organization.
- Qualifications:
- Bachelor’s degree in Computer Science, Computer Engineering, relevant technical field, or equivalent practical experience.
- 7+ years of Python development experience.
- 7+ years of SQL experience.
- 5+ years of experience with workflow management engines (i.e. Airflow, Luigi, Prefect, Dagster, Digdag, Google Cloud Composer, AWS Step Functions, Azure Data Factory, UC4, Control-M).
- 7+ years experience with Data Modeling.
- Communications skills.
- Experience understanding requirements, analyzing data, discovering opportunities, addressing gaps and communicating them to multiple individuals and stakeholders.
- 7+ years experience in custom ETL design, implementation, and maintenance.
- Experience working with cloud or on-prem Big Data/MPP analytics platforms (i.e. Snowflake, AWS Redshift, Google BigQuery, Azure Data Warehouse, Netezza, Teradata, or similar).
The Data Analyst Meta/Facebook Interview
Overview of Data Analyst at Meta/Facebook
- Compensation:
- Salary range: $125,000 to $160,000 USD*
-
- Bonus: to $15,000 to $25,000
- Equity: $20,000 to $60,000
- Responsibilities:
- Build new analytics and reporting capabilities to support program evaluation and operations
- Handle ad hoc reporting and analytics requests, while addressing stakeholder long-term needs and driving insights for Human Resource Partners and Executives using existing dashboard, Human Resource Information System (HRIS) data, and leveraging our people data ecosystem
- Effectively communicate with cross-functional partners and internal teams to deliver solutions in a timely fashion
- Proactively manage stakeholder expectations, manage escalations and resolve issues in a timely manner
- Qualifications:
- 4+ years of experience working with SQL or relational database
- 2+ years of experience with data visualization tools (e.g., ggplot2, Tableau)
- Experience initiating and driving projects to completion with minimal guidance
- Experience working in a fast-paced and demanding environment
- Experience having effective conversations with clients about their support needs and requirements, managing the intake process, and asking the right questions to scope and solve the requests
- Demonstrated judgment and discretion when dealing with highly sensitive people data and business issue.
What SQL Questions Get Asked at Facebook?
It’s helpful to prep when you have an idea of the SQL questions that get asked at Facebook. Essentially, these questions fall into two categories:
1) Definition-based questions – Definition questions are used to quickly assess your SQL knowledge. These will be simple questions like, “What is a JOIN?” or more theoretical questions like “Why would you use an index in SQL?” You’ll need a solid grasp of key terms and concepts to nail this portion of the Facebook interview.
2) Writing queries – Facebook interviews ask a lot of SQL questions. And the majority tend to fall into this category. In Facebook SQL interviews, you’ll likely be asked to write a query using two or more datasets. These are generally based on Facebook (or Instagram) cases.
How Much SQL Is Asked in Facebook Interview?
To answer this question, it really depends on the role. In some positions, like product analysts – for example – you’ll use SQL everyday, and will likely be asked a wide range of SQL query questions. Other roles, like data engineers, will use SQL for data processing and database management, which might ask more theoretical questions.
Here’s a look at SQL by role:
- Product Strategist – Interviews for strategist roles require the ability to quickly isolate insights from product and user data. Focus your prep on writing beginner-to-advanced queries in SQL.
- Data Analyst – Facebook employees analysts in several capacities, including product, community relations and business intelligence. These roles will require the ability to write SQL using customer and product data.
- Data Engineer – Data engineer roles will get asked query questions. But also more theoretical SQL questions around query optimization, database management, and database design.
- Data Scientist – Many Facebook data scientist roles are aligned with analytics, e.g. using analytics to make data-driven product decisions. SQL (as well as a scripting language like Python) are important skills. These questions tend to ask query questions – from basics, to more complex queries.
SQL Concepts for Facebook Interview
Here are some sample Facebook SQL questions that are definitions, as well as theoretical. As you study, focus on those definitions (especially being able to explain them in layman’s terms), as well as how they might apply theoretically.
Q1. What is a foreign key in SQL? What role does it play?
A foreign key is a field or multiple fields in one table that can refer back to the primary key in another. The table with the primary key is referred to as the parent or referenced table, while the one with the foreign key is the child table. Foreign keys are used to provide the referential integrity between tables.
Q2. Are blank spaces or zero values treated the same as NULL?
No, NULL is not the same as a zero or blank space. Instead, NULL is used in the absence of any value. In other words, the value is unavailable, unknown, unassigned or not appropriate. Zeroes and blank spaces are treated differently, and they can be compared to other zeroes or blank spaces, respectively. NULL cannot be compared to another NULL.
Q3. What is meant by SQL injection? What would be the first step in preventing or mitigating an attack?
SQL injection, also known as SQLI, is a type of vulnerability that uses malicious SQL code to give attacks access to the backend database. Attackers can then manipulate the database and gain access to private information like user lists and customer details.
One of the first steps would be input validation, to identify the illegitimate user inputs.
Q4. What’s the difference between IN and BETWEEN operators?
Both allow you to find multiple values from the table. But a key difference is the type of data you are selecting with these operators. For example, BETWEEN selects a range of data between two values. Alternatively, IN allows you select multiple values.
Q5. What is a cursor?
In SQL, a cursor is a temporary memory or workstation. They store database tables, and in SQL there are two main types: 1) implicit cursors and 2) explicit cursors. Implicit cursors are allocated by the SQL server when users perform DML operations. Explicit cursors are based on user inputs.
Q6. Explain what a trigger is in SQL. When would you use a trigger?
A trigger is a stored procedure that automatically runs when a certain event occurs in the database server. For example, DML triggers run when a user tries to modify data. Triggers can be used to:
- Audit database activity
- Implement rules
- To enforce referential integrity
Facebook SQL Coding Questions
In the technical screen, you’ll be asked a range of query-based SQL questions. These will ask you to write queries based on provided datasets. The best prep strategy is to practice and write lots of sample queries aligned to real case studies. Here are questions that will help you develop that skill:
Q1: Write a SQL query to create a histogram of number of comments per user in the month of January 2020. Assume bin buckets class intervals of one.
users table:
| columns | type |
|-----------------|----------|
| id | integer |
| name | string |
| created_at | datetime |
| neighborhood_id | integer |
| mail | string |comments table:
| columns | type |
|------------|----------|
| user_id | integer |
| body | text |
| created_at | datetime |Hint: Since a histogram is just a display of frequencies of each user, all we really need to do is get the total count of user comments in the month of January 2020 for each user, and then group by that count.
Q2: In the table below, column `action` represents either (‘post_enter’, ‘post_submit’, ‘post_canceled’) for when a user starts a post (enter), ends up canceling it (cancel), or ends up posting it (submit). Write a query to get the post success rate for each day in the month of January 2020.
events table:
| columns | type |
|------------|----------|
| id | integer |
| user_id | integer |
| created_at | datetime |
| action | string |
| url | string |
| platform | string |Hint: Let’s see if we can clearly define the metrics we want to calculate before just jumping into the problem. We want post success rate for each day over the past week. How would we get that metric?
We can assume post success rate can be defined as: (total posts created) / (total posts entered)
Additionally, since the success rate must be broken down by day, we must make sure that a post that is entered must be completed on the same day.
Now that we have these requirements, it’s time to calculate our metrics. We know we have to GROUP BY the date to get each day’s posting success rate. We also have to break down how we can compute our two metrics of total posts entered and total posts actually created.
Q3: We want to build a naive recommender and we’re given two tables, one table called `friends` with a user_id and friend_id columns representing each user’s friends, and another table called `page_likes` with a user_id and a page_id representing the page each user liked. Write an SQL query to create a metric to recommend pages for each user based on recommendations from their friends liked pages.
friends table:
| columns | type |
|-----------|---------|
| user_id | integer |
| friend_id | integer |page likes table:
| columns | type |
|---------|---------|
| user_id | integer |
| page_id | integer |Solution: We can start by visualizing what kind of output we want from the query. Given that we have to create a metric for each user to recommend pages, we know we want something with a user_id and a page_id along with some sort of recommendation score.
How can we easily represent the scores of each user_id and page_id combo? One naive method would be to create a score by summing up the total likes by friends on each page that the user hasn’t currently liked. The max value on our metric would be the most recommendable page.
The first thing we have to do then is to write a query to associate users to their friends liked pages. We can do that easily with an initial join between the two tables.
Q4: Given the following three tables that represent customer transactions and customer attributes, write a query to get the average order value by gender.
transactions table:
| columns | type |
|------------|----------|
| id | integer |
| user_id | integer |
| created_at | datetime |
| product_id | integer |
| quantity | integer |users table:
| columns | type |
|---------|---------|
| id | integer |
| name | varchar |
| sex | varchar |products table:
| columns | type |
|---------|---------|
| id | integer |
| name | string |
| price | float |Q5: Say our example output from the query in Question 4 is:
Men
– AOV: $46.3
– Total purchases: 2500
– Unique purchasers: 1500
Women
– AOV: $50.2
– Total purchases: 3500
– Unique purchasers: 500
Would the difference in AOV (average order value) be significant?
Note: remember to round your answer to two decimal places!
Q6 (Part 1): You’re given a table that represents search results from searches on Facebook. The query column is the search term, position column represents each position the search result came in, and the rating column represents the human rating of the search result from 1 to 5 where 5 is high relevance and 1 is low relevance.
Write a query to compute a metric to measure the quality of the search results for each query.
This is an unusual SQL problem, given it asks to define a metric and then write a query to compute it. Generally, this should be pretty simple. Can we rank by the metric and figure out which query has the best overall results?
For example, if the search query for ‘tiger’ has 5s for each result, then that would be a perfect result.
The way to compute that metric would be to simply take the average of the rating for all of the results. In which the query can very easily be:
SELECT query, ROUND(AVG(rating), 2) AS avg_rating
FROM search_results
GROUP BY 1Q6 (Part 2): You want to be able to compute a metric that measures the precision of the above ranking system based on position. For example, if the results for dog and cat are:
|
query |
result_id |
position |
rating |
notes |
|
dog |
1000 |
1 |
2 |
picture of hotdog |
|
dog |
998 |
2 |
4 |
dog walking |
|
dog |
342 |
3 |
1 |
zebra |
|
cat |
123 |
1 |
4 |
picture of cat |
|
cat |
435 |
2 |
2 |
cat memes |
|
cat |
545 |
3 |
1 |
pizza shops |
We would rank ‘cat’ as having a better search result ranking precision than ‘dog’ based on the correct sorting by rating.
Write a query to create a metric that can validate and rank the queries by their search result precision. Round the metric (avg_rating column) to 2 decimal places.
The precision metric is a little more difficult now that we have to account for a second factor, which is position. We now have to find a way to weight the position in accordance to the rating to normalize the metric score.
This type of problem set can get very complicated if we wanted to dive deeper into it. However, the question is clearly more marked towards being practical in figuring out the metric and developing an easy SQL query, rather than developing a search ranking precision scale that optimizes for something like CTR.
To solve the problem, it’s helpful to look at the example to construct an approach towards a metric. For example, if the first result is rated at 5 and the last result is rated at a 1, that’s good. Even better, however, is if the first result is rated 5 and the last result is also rated 5. Bad is if the first result is 1 and the last result is 5.
However, if we use the approach from Part 1, we’ll get the same metric score no matter which way the values are ranked by position. So how do we factor position into the ranking?

